利用互联网检索优化RAG模型的时效性问题
2024年6月26日 · 378 字 · 2 分钟
在当今信息爆炸的时代,我们每天都在生成和消费海量的数据。对于依赖大量最新数据进行决策的领域,如金融分析、市场研究或实时新闻报道,传统的机器学习模型可能难以满足需求,因为它们通常在训练后便固定下来,难以适应快速变化的信息环境。近年来,Retrieval-Augmented Generation(RAG)模型因其结合了检索和生成的能力而受到关注。然而,RAG模型也面临着时效性问题。本文将探讨如何通过互联网检索和大型语言模型(LLM)来优化RAG模型的时效性。
RAG模型及其时效性挑战
RAG模型通过将检索组件与生成组件相结合,提高了模型对特定查询的响应能力。然而,如果模型仅依赖于预先训练好的数据,它可能无法提供最新的信息。例如,在体育赛事中,比赛结束后,人们期望模型能够提供最新的比分和统计数据,而不是过时的信息。
为了解决时效性问题,我们可以利用互联网搜索引擎作为数据源。搜索引擎能够索引最新的网页内容,为我们提供实时更新的数据。通过编写特定的爬虫或使用API,我们可以从搜索引擎获取与查询相关的最新网页内容。
获取到最新的语料后,我们可以将其输入到大型语言模型中进行内容生成。LLM的强大之处在于它们能够理解和生成自然语言,这使得它们成为生成连贯、准确和相关文本的理想选择。
基于搜索引擎的RAG例子
接下来笔者将以一个基于百度搜索引擎以及月之暗面大模型的RAG例子进行逐步示范:
安装组件
pip install requests
pip install bs4
pip install langchain_openai
pip install langchain_core
构建检索器
检索器需要继承langchain_core.runnables.Runnable并实现invoke方法,因此我们可以以任意数据源来构建检索器,而不仅仅是搜索引擎,下面是基于百度搜索引擎查询关键字并提取文本的代码:
class CustomWebSearchRetriever(Runnable):
def __init__(self, search_url, headers=None):
self.search_url = search_url
self.headers = headers or {}
def retrieve(self, query):
response = requests.get(self.search_url, headers=self.headers, params={'wd': query})
soup = BeautifulSoup(response.text, 'html.parser')
search_results = soup.find_all('div', class_='result')
print(f"searched {len(search_results)} results")
return '\n'.join([result.get_text() for result in search_results])
def invoke(self, input: Input, config: Optional[RunnableConfig] = None) -> Output:
# invoke方法调用retrieve方法,并返回结果
print('querying', str(input))
return self.retrieve(input)
初始化LLM
笔者使用的是月之暗面,在前面的内容中我提到过Langchain提供了非常多的LLM,比如OpenAI的ChatGPT以及开源的llama3等。
llm = ChatOpenAI(
model_name='moonshot-v1-8k',
temperature=0.75,
openai_api_base='https://api.moonshot.cn/v1',
openai_api_key='秘钥',
streaming=False,
)
初始化检索器
# 配置搜索引擎的URL和headers
search_url = "https://www.baidu.com/s" # 这里需要替换为实际的搜索引擎URL
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
# 初始化自定义的WebSearchRetriever
retriever = CustomWebSearchRetriever(search_url, headers)
构建执行链
Langchain需要构建一个执行链来进行指定工作,前面的文章中已经使用过本地向量数据库构建了一个执行链,本文是类似的,唯一的区别是提示词不同:
def search_and_generate(query):
# 使用检索器搜索
template = """你是一个帮助用户完成信息检索的智能助理,你的职责是根据提供的上下文回答用户的问题。
此外,你还需要遵守下列约定:
1、如果你不知道问题的答案,直接说不知道
上下文: {context}
我的问题是: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# 开始查询&生成
return rag_chain.invoke(query)
执行查询
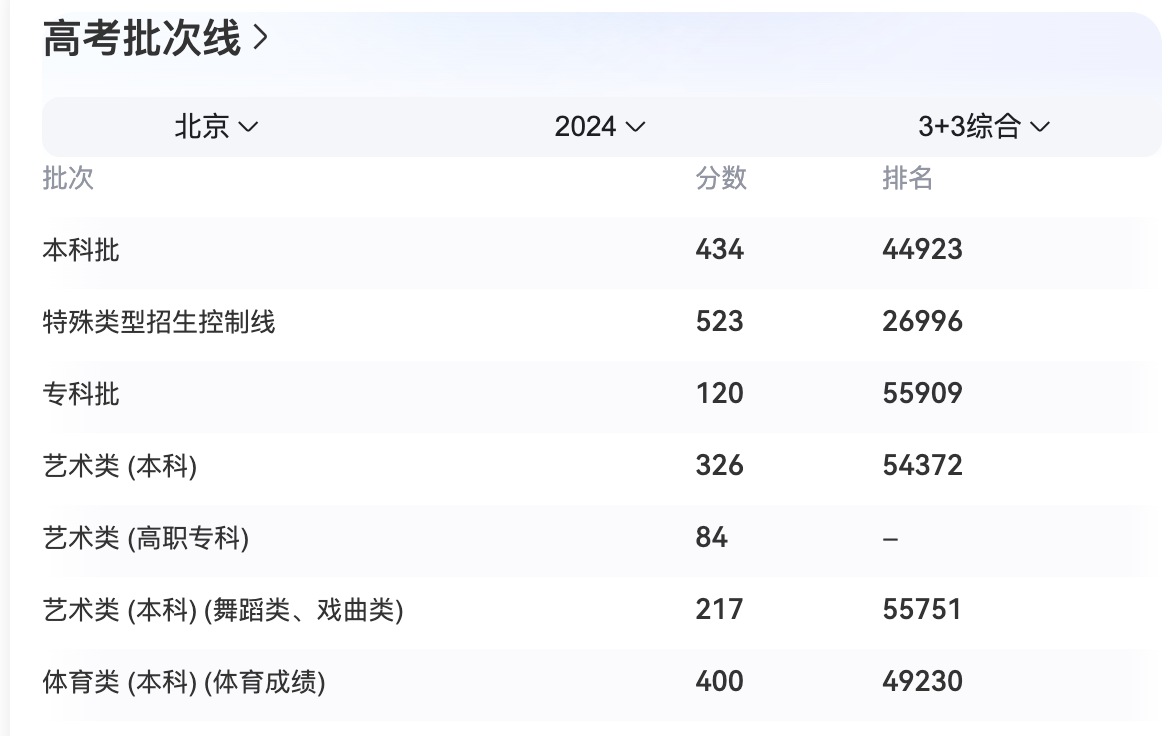
最近几天出了高考分数线,我们问一下RAG:
# 定义你想要搜索的问题
query = "告诉我2024年的北京高考分数线"
# 执行搜索并生成回答
answer = search_and_generate(query)
print(answer)
输出如下
querying 告诉我2024年的北京高考分数线
searched 9 results
2024年北京高考普通本科录取控制分数线为434分,特殊类型招生控制分数线为523分。同时,普通专科录取控制分数线为120分(语数外三科总分)。
这是在线检索得到的结果,完美!
结论
通过结合互联网检索和LLM,我们可以显著提高RAG模型的时效性,使其能够提供最新的信息和内容。这种方法不仅适用于体育赛事报道,还可以扩展到其他需要实时数据的领域。随着技术的不断进步,我们可以期待更加智能和灵活的RAG模型,以满足不断变化的信息需求。
本文代码如下:
import requests
from bs4 import BeautifulSoup
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough, Runnable, RunnableConfig
from langchain_core.runnables.utils import Input, Output
from typing import Optional
# 定义一个自定义的WebSearchRetriever
class CustomWebSearchRetriever(Runnable):
def __init__(self, search_url, headers=None):
self.search_url = search_url
self.headers = headers or {}
def retrieve(self, query):
# 保持之前的retrieve方法不变
response = requests.get(self.search_url, headers=self.headers, params={'wd': query})
soup = BeautifulSoup(response.text, 'html.parser')
search_results = soup.find_all('div', class_='result')
print(f"searched {len(search_results)} results")
return '\n'.join([result.get_text() for result in search_results])
def invoke(self, input: Input, config: Optional[RunnableConfig] = None) -> Output:
# invoke方法调用retrieve方法,并返回结果
print('querying', str(input))
return self.retrieve(input)
# 初始化语言模型
# llm = OpenAI(
# temperature=0,
# api_key="sk-zgvGceDChpJjVedic1gFP0MFr8jpU4Oo0uNy0OM29dKRuqqz",
# base_url="https://api.moonshot.cn/v1/chat",
# model='moonshot-v1-8k',
# )
llm = ChatOpenAI(
model_name='moonshot-v1-8k',
temperature=0.75,
openai_api_base='https://api.moonshot.cn/v1',
openai_api_key='sk-zgvGceDChpJjVedic1gFP0MFr8jpU4Oo0uNy0OM29dKRuqqz',
streaming=False,
)
# 配置搜索引擎的URL和headers
search_url = "https://www.baidu.com/s" # 这里需要替换为实际的搜索引擎URL
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
# 初始化自定义的WebSearchRetriever
retriever = CustomWebSearchRetriever(search_url, headers)
# 定义一个函数来执行搜索并获取结果
def search_and_generate(query):
# 使用检索器搜索
template = """你是一个帮助用户完成信息检索的智能助理,你的职责是根据提供的上下文回答用户的问题。
此外,你还需要遵守下列约定:
1、如果你不知道问题的答案,直接说不知道
上下文: {context}
我的问题是: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# 开始查询&生成
return rag_chain.invoke(query)
# 定义你想要搜索的问题
query = "告诉我2024年的北京高考分数线"
# 执行搜索并生成回答
answer = search_and_generate(query)
print(answer)
- 本文作者: xialeistudio
- 本文链接: 利用互联网检索优化RAG模型的时效性问题
- 版权声明: 「署名-非商业性使用-相同方式共享 4.0 国际」
