Beyond GPT-3.5! Llama3 Personal Computer Local Deployment Tutorial.
April 24, 2024 · 581 words · 3 min
On April 18th, Meta announced Llama3 on their official blog, marking a significant leap in the field of artificial intelligence. Based on my personal experience, Llama3’s 8B model has surpassed GPT-3.5, and most importantly, Llama3 is open source, allowing us to deploy it on our own!
In this article, I will share how to deploy Llama3 on a personal computer, giving you your own GPT-3.5+!
Many readers may be concerned that their personal computer’s hardware configuration is insufficient for local deployment. However, this concern is unnecessary. For reference, I used a MacBook M2 Pro (2023 model) with the following primary hardware specifications:
- 10-core CPU
- 16 GB RAM
The deployment steps are roughly as follows:
- Install Ollama
- Download Llama3
- Install Node.js
- Deploy the WebUI
Install Ollama
Ollama can be simply understood as a client, which enables interaction with large models. Readers can go to https://ollama.com/download to download the corresponding client according to the operating system type. For example, I downloaded macOS.
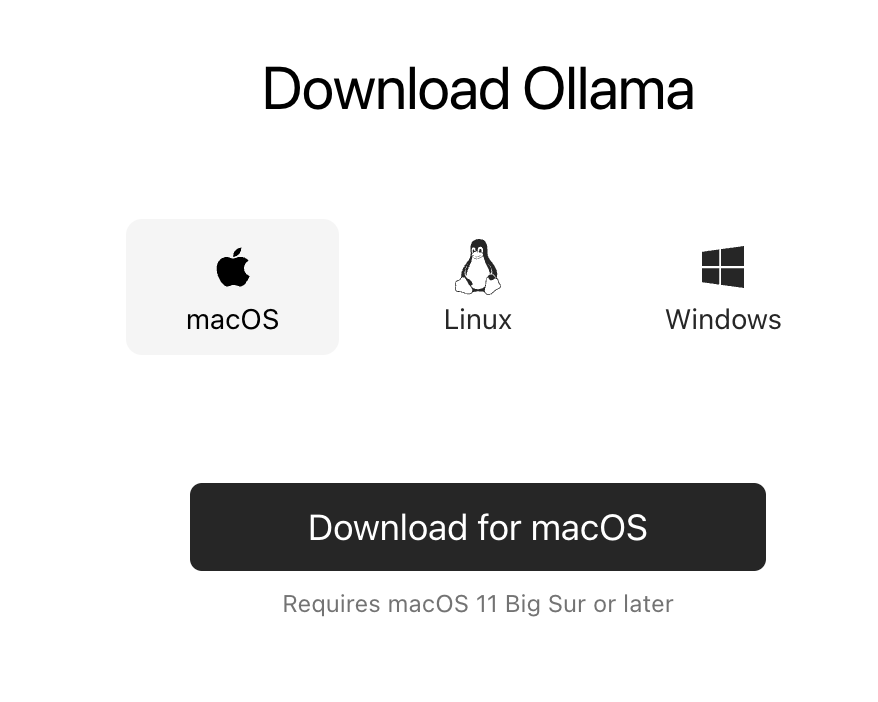
After downloading, open it and click Next and Install directly to install ollama to the command line. After the installation is complete, the interface will prompt ollama run llama2. There is no need to execute this command because we want to install llama3.
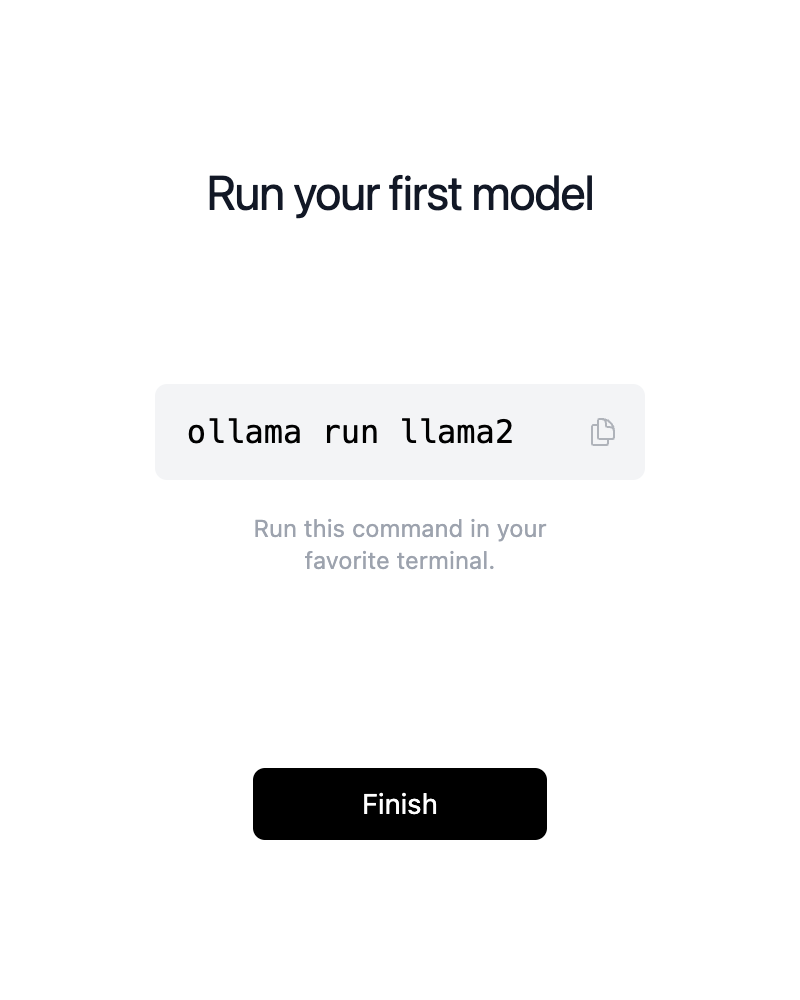
Download Llama3
Open new CMD/Terminal, execute the following command:
ollama run llama3
The program will automatically download the Llama3 model file. The default is 8B, which is an 8 billion parameter version. It can be run on a personal computer.
After successfully downloading the model, you will enter the interactive interface. We can ask questions directly on the terminal. For example, I asked Who are you?, and Llama3 answered it in almost seconds.
➜ Projects ollama run llama3
>>> who are you?
I'm LLaMA, a large language model trained by a team of researcher at Meta
AI. I'm here to chat with you and answer any questions you may have.
I've been trained on a massive dataset of text from the internet and can
generate human-like responses to a wide range of topics and questions. My
training data includes but is not limited to:
* Web pages
* Books
* Articles
* Research papers
* Conversations
I'm constantly learning and improving my responses based on the
conversations I have with users like you.
So, what's on your mind? Do you have a question or topic you'd like to
discuss?
Install Node.js
There are many WebUIs that support Ollama. I have experienced the most popular WebUI (https://github.com/open-webui/open-webui), which requires Docker or Kubernetes deployment, which is a bit troublesome, and the image is about 1G.
I recommend using ollama-webui-lite (https://github.com/ollama-webui/ollama-webui-lite), which is very lightweight and only relies on Node.js.
You can go to (https://nodejs.org/en/download) to download the corresponding Node.js according to their operating system and CPU chip type and install it.
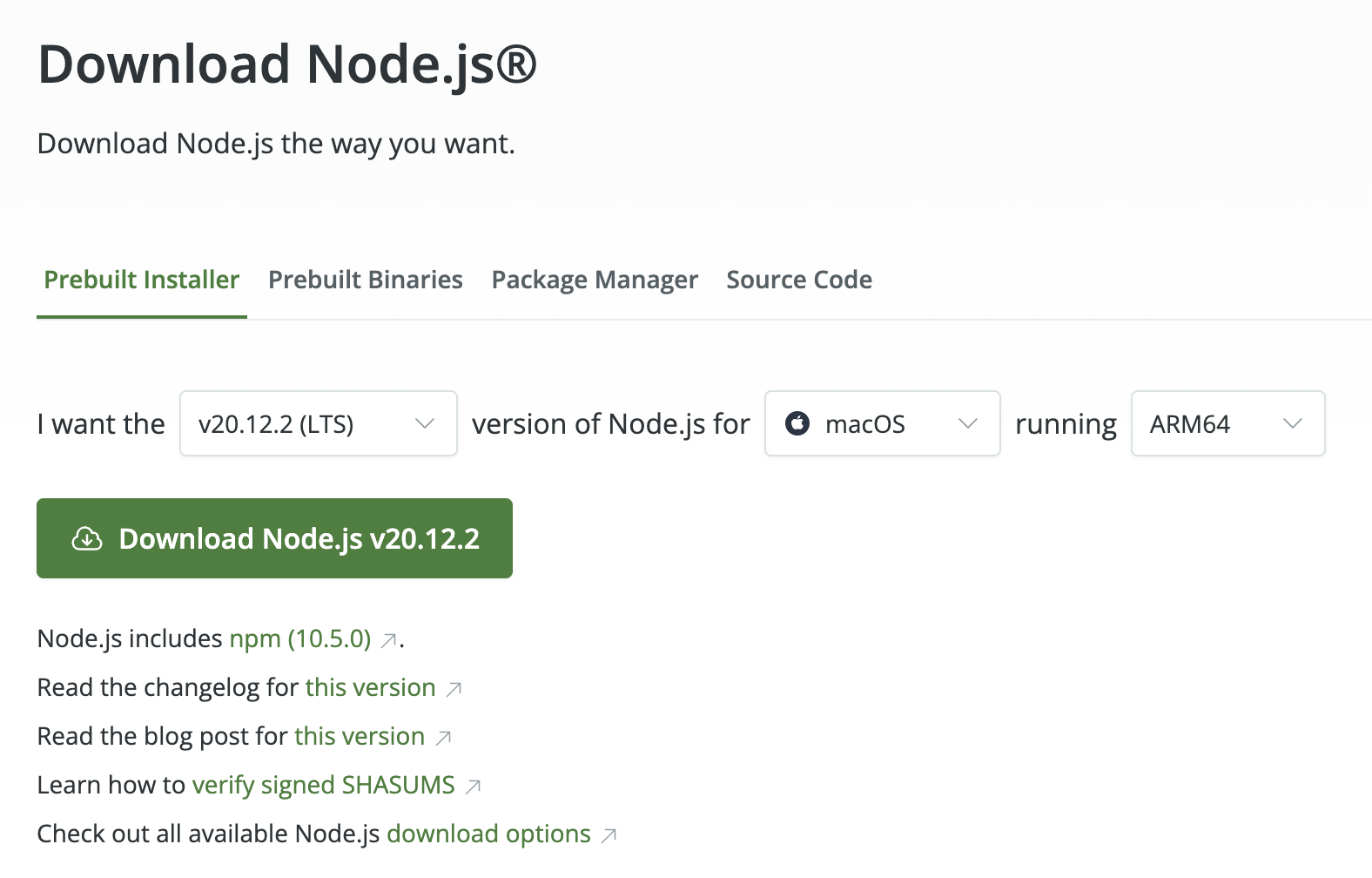
WebUI Deployment
Open CMD/Terminal, exectute the following commands to deploy the WebUI:
git clone https://github.com/ollama-webui/ollama-webui-lite.git
cd ollama-webui-lite
npm install
npm run dev
As we can see, WebUI is already listening on the local port 3000:
> [email protected] dev
> vite dev --host --port 3000
VITE v4.5.2 ready in 765 ms
➜ Local: http://localhost:3000/
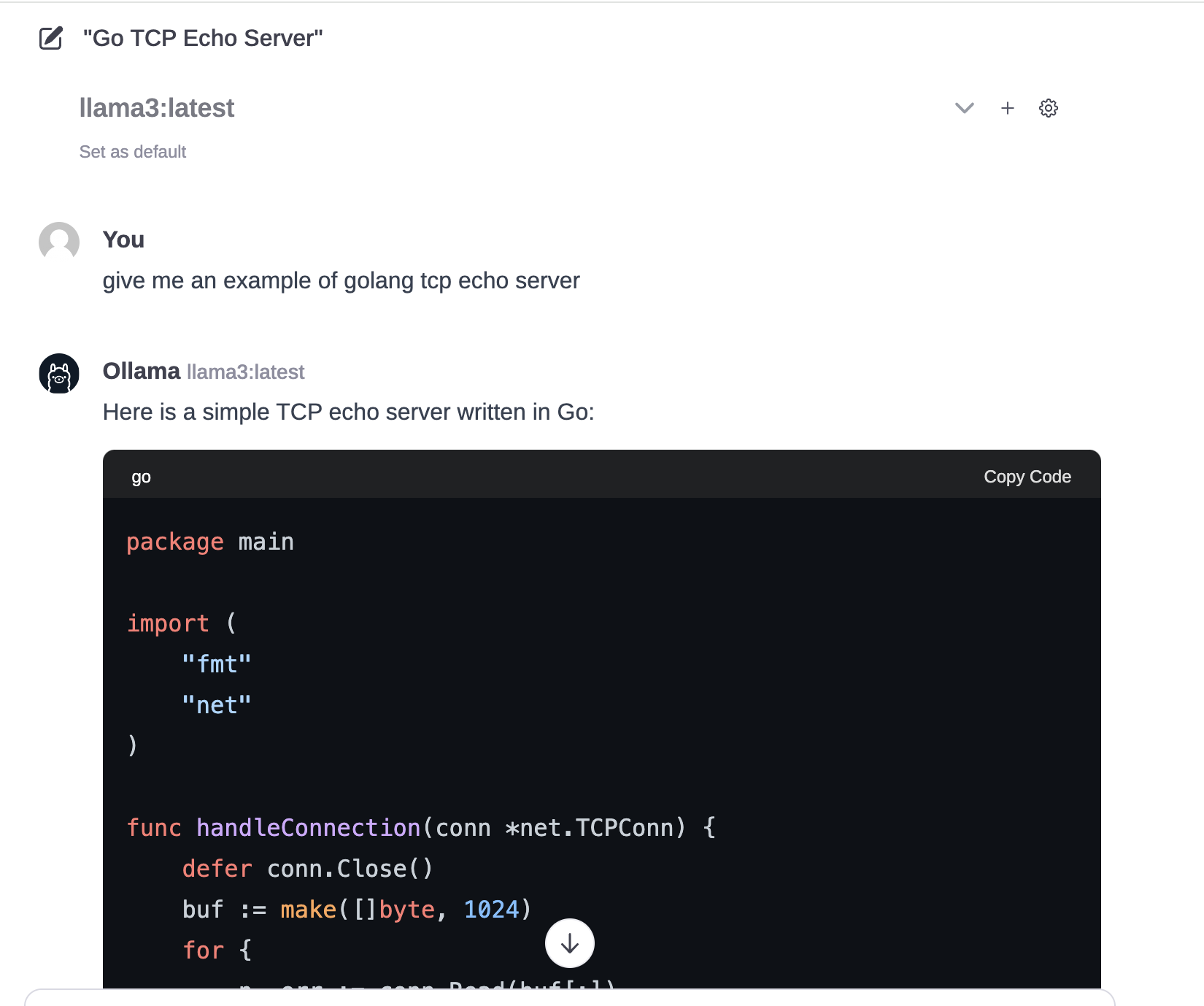
Open the browser and visit http://localhost:3000, you can see the screenshot as shown below. By default, the model is not selected. You need to click on the arrow shown in the screenshot to select the model.

I gave the model an example of writing a Golang Echo Server, and it started printing results in about 5 seconds, which is very fast.
Any questions? Leave a comment!